QuantumBlack, the advanced analytics firm we acquired in 2015, has now launched Kedro, an open source tool created specifically for data scientists and engineers. It is a library of code that can be used to create data and machine-learning pipelines. For our non-developer readers, these are the building blocks of an analytics or machine-learning project. “Kedro can change the way data scientists and engineers work,” explains product manager Yetunde Dada, “making it easier to manage large workflows and ensuring a consistent quality of code throughout a project.”
McKinsey has never before created a publicly available, open source tool. “It represents a significant shift for the firm,” notes Jeremy Palmer, CEO of QuantumBlack, “as we continue to balance the value of our proprietary assets with opportunities to engage as part of the developer community, and accelerate as well as share our learning.”
The name Kedro, which derives from the Greek word meaning center or core, signifies that this open-source software provides crucial code for ‘productionizing’ advanced analytics projects. Kedro has two major benefits: it allows teams to collaborate more easily by structuring analytics code in a uniform way so that it flows seamlessly through all stages of a project. This can include consolidating data sources, cleaning data, creating features and feeding the data into machine-learning models for explanatory or predictive analytics.
More: www.mckinsey.com; https://github.com/quantumblacklabs/kedro
 What are the main features of Kedro?
What are the main features of Kedro?

1. Project template and coding standards
- A standard and easy-to-use project template
- Configuration for credentials, logging, data loading and Jupyter Notebooks / Lab
- Test-driven development using
pytest - Sphinx integration to produce well-documented code
2. Data abstraction and versioning
- Separation of the compute layer from the data handling layer, including support for different data formats and storage options
- Versioning for your data sets and machine learning models
3. Modularity and pipeline abstraction
- Support for pure Python functions,
nodes, to break large chunks of code into small independent sections - Automatic resolution of dependencies between
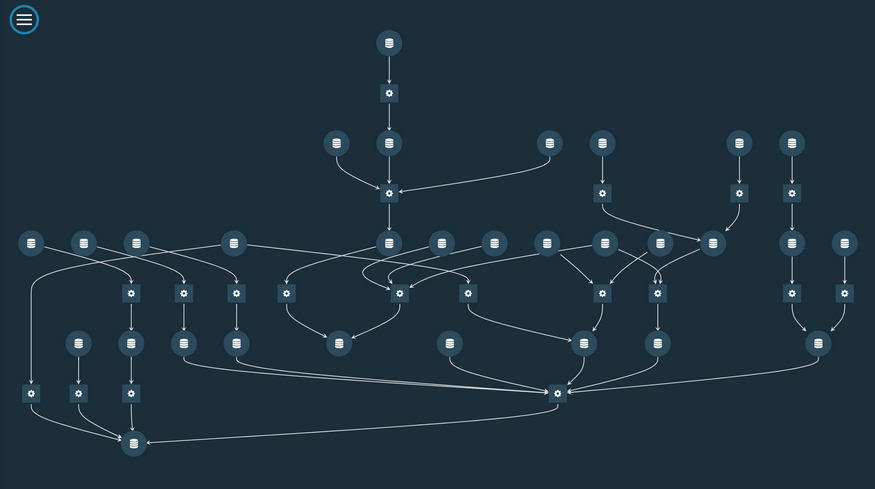
nodes - (coming soon) Visualise your data pipeline with Kedro-Viz, a tool that shows the pipeline structure of Kedro projects
Note: Read our FAQs to learn how we differ from workflow managers like Airflow and Luigi.
4. Feature extensibility
- A plugin system that injects commands into the Kedro command line interface (CLI)
- List of officially supported plugins:
- (coming soon) Kedro-Airflow, making it easy to prototype your data pipeline in Kedro before deploying to Airflow, a workflow scheduler
- Kedro-Docker, a tool for packaging and shipping Kedro projects within containers
- Kedro can be deployed locally, on-premise and cloud (AWS, Azure and GCP) servers, or clusters (EMR, Azure HDinsight, GCP and Databricks)